前回は、Prediction Oneが、与えられたデータを元に、クリック率向上に効果的な検索キーワードを学習したところまででした。
今回は、この学習結果から、新たなキーワードの組み合わせによるクリック率をAI予測します。
改めていうまでもありませんが、このソフトで、クリック率の上がる魔法のキーワードが見つかるわけではありません。
機械学習に使用したCSVデータの中で使用されていたキーワードのうち、クリック率アップに寄与しそうなキーワードの組み合わせが分かるだけです。
それでは、実際に調べたいキーワードを記載した、CSVファイルを用意します。2,3,4行目に、クリック率アップに寄与しそうな3種類のキーワードの組み合わせを書いています。
クリック数や表示回数は、全くデータが無いため空欄のままです。こんな状態でも予測できるか、試してみます。

Prediction Oneの、”新規予測”ボタンを押して、”ファイルを開く”欄にこのファイルをドラッグするだけで、予測結果が表示されます。
(”予測理由を追加”ボタンをクリックしておきます。)
そして、表示された結果がこれ。↓
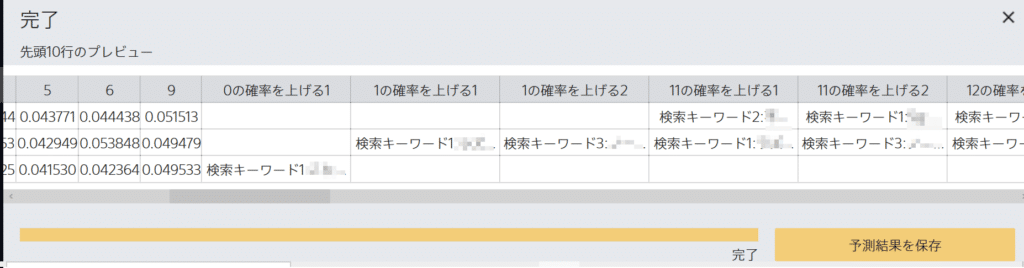
それぞれの項目の確率を上げるキーワードの候補が表示されています。
結果は、……正直言って、ピンときません。
というのも私の場合、投稿数は110件程度で、クリックされたときのキーワードの数も300程度。その中で寄与率の高かったキーワードを適当に選んで、予測にかけただけです。
一般的に機械学習で元となるサンプルデータは数千から数万必要といわれており、今回はデータ量が十分でなく、有意な結果が得られなかったと思われます。
また、予測したいキーワードも単純に抜き出しただけで、そのキーワードに沿ったコンテンツまで考えられておらず、データの欠損もあるため、サンプルの前処理(質)も適切だったとはいえません。
逆に言えば、機械学習には、良質な一定数のサンプルデータが必要で、機械学習に適したデータの前処理が必要です。
これを聞いて、ちょっと拍子抜けされた人もいるんじゃないでしょうか?
それでも、機械学習のさわりの部分、特にデータ数やデータの前処理の重要性を素人なりに肌感覚で知る事ができた事はよかったです。
機械学習で、良く言われることですが、Garbage In Garbage Out.
裏を返せば、有用なデータからしか有用な結果は得られない。ということ。
加えて、データの前処理が適切でないと、有用な結果は得られません。
今回の例でいうと、キーワード1つに対し、そのキーワードだけの表示回数/クリック数に加え、キーワードが複数組み合わされた時の表示回数/クリック数のデータは必須。
更には、一度も表示されなかったキーワードデータも加えて、初めて有用なキーワードの組み合わせの予測ができる、ということだと思います。
Prediction Oneは、残念ながら学習に使用していないキーワードの予想はできないようなので、もしフリーワードのクリック予測がしたい場合は、ありとあらゆるキーワードのサンプルを学習させておく必要があります。現実的には不可能ですが。
それでも、簡単な手順でAI分析ができるソフトって他には見当たらないので、ソニーさんに頑張ってもらって、はやく次期バージョンを、無料リリースしてほしいです。
Follow me!